在当今数据驱动的时代,实时处理海量流式数据已成为企业获取即时洞察、做出敏捷决策的关键能力。Apache Kafka,作为一个高吞吐、可扩展、分布式的流处理平台,正是这一领域的核心引擎。本文将提供一份实战指引,深入探讨如何利用Kafka构建高效、可靠的实时数据处理流水线。
一、理解Kafka的核心架构与数据模型
Kafka的核心是一个基于发布-订阅模型的分布式消息系统。其基本组件包括:
- Producer(生产者):将数据流发布到Kafka的指定主题(Topic)。
- Topic(主题):数据流的分类或名称,是数据发布和订阅的逻辑单元。一个主题可以被分为多个分区(Partition),以实现并行处理和水平扩展。
- Partition(分区):每个分区是一个有序、不可变的消息序列。分区是Kafka实现高吞吐和可扩展性的基础,数据被追加到分区尾部,并为每个消息分配一个偏移量(Offset)作为唯一标识。
- Consumer(消费者):从主题的一个或多个分区订阅并拉取数据进行处理。消费者可以组成消费者组(Consumer Group)来实现负载均衡和容错。
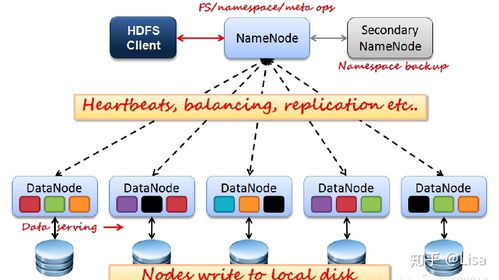
- Broker(代理):Kafka集群中的单个服务器节点,负责存储数据和处理客户端请求。多个Broker构成一个高可用的集群。
这种架构使得Kafka能够以极低的延迟处理每秒数百万条消息,并持久化存储数据流,为后续的实时流处理提供了坚实的数据源。
二、构建实时数据处理流水线的实战步骤
步骤1:设计与规划数据流
明确数据源、数据格式、数据量级和处理目标。例如,数据源可能是网站点击流、物联网传感器、应用程序日志或数据库变更日志。根据业务需求,规划需要创建哪些主题、每个主题的分区数(通常与下游消费者的并行处理能力相关)以及数据的保留策略。
步骤2:高效生产数据
生产者客户端应合理配置,如使用批量发送(batch.size)、压缩(compression.type)以提高吞吐量,并正确设置acks参数(如acks=all)来平衡数据可靠性与性能。确保序列化(如Avro、Protobuf)高效且向前/向后兼容。关键是将数据发送到正确的分区,可以利用消息键(Key)来保证同一键的消息总是进入同一分区,从而维持顺序性。
步骤3:可靠消费与处理数据
消费者是数据处理逻辑的核心载体。实战要点包括:
- 消费者组管理:合理设置消费者组ID,实现自动的负载均衡(分区分配给组内消费者)和故障转移。
- 位移(Offset)管理:理解自动提交与手动提交的优劣。对于精确一次(Exactly-Once)处理语义,通常需要结合幂等生产者和事务API,并谨慎管理消费者位移。手动提交位移可以在数据处理成功后执行,避免数据丢失或重复。
- 处理逻辑:消费到数据后,处理逻辑可以是简单的过滤、转换、丰富,也可以是复杂的流式聚合、窗口计算或模式检测。对于复杂处理,推荐使用Kafka Streams或ksqlDB这类原生流处理库,它们提供了高级DSL和Exactly-Once语义保证,极大简化了状态化流处理应用的开发。
步骤4:连接外部系统(Kafka Connect)
Kafka生态中的Kafka Connect框架,专门用于在Kafka和外部系统(如数据库、数据仓库、搜索引擎、云存储)之间进行可扩展、可靠的数据传输。利用现成的连接器(Connector),可以轻松地将数据从源系统导入Kafka,或将处理后的结果从Kafka导出到目标系统,无需编写繁琐的生产者/消费者代码。
步骤5:监控、运维与性能调优
一个健壮的流水线离不开监控和调优:
- 监控指标:密切关注集群、Broker、主题、分区的关键指标,如吞吐量、延迟、请求错误率、磁盘使用率、网络IO、消费者滞后(Lag)等。Kafka提供了丰富的JMX指标,可集成到Prometheus、Grafana等监控系统中。
- 性能调优:根据瓶颈调整参数,例如增加分区数以提高并行度,调整Broker的日志刷写和留存策略,优化网络和JVM配置等。
- 容错与高可用:确保副本因子(Replication Factor)大于1,并正确配置最小同步副本(
min.insync.replicas),以容忍Broker故障而不丢失数据。
三、典型应用场景与最佳实践
- 实时数据管道:作为中央神经系统,连接不同的数据源和应用,实现数据的实时流动。
- 实时监控与告警:处理日志和指标流,实时检测异常并触发告警。
- 事件驱动架构:将应用状态变化作为事件发布,其他服务订阅这些事件做出反应,实现服务间的松耦合。
- 流式ETL:对流入的数据进行实时清洗、转换和加载到数据湖或数据仓库。
最佳实践:
1. 根据吞吐量和顺序性需求谨慎设计分区策略。
2. 为关键业务数据启用端到端的事务和幂等性,保障处理语义。
3. 采用Schema Registry(如Confluent Schema Registry)管理数据格式的演进,确保上下游兼容。
4. 将处理逻辑尽量靠近数据,优先使用Kafka Streams进行流处理,以降低延迟和系统复杂性。
5. 建立全面的监控告警体系,对消费者滞后等关键指标设置阈值。
通过深入理解Kafka的架构原理,并遵循上述实战指引与最佳实践,您将能够有效地构建和运维一个能够应对实时海量数据挑战的、健壮且高效的流式数据处理系统。Kafka不仅仅是消息队列,它已成为现代实时数据基础设施的基石。