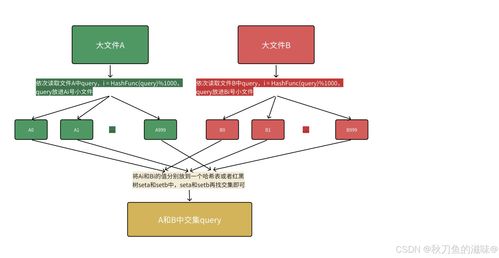
在当今大数据时代,处理海量数据已成为各类系统面临的共同挑战。如何在海量数据中快速判断某个元素是否存在,如何高效去重,如何节省存储空间?针对这些问题,位图(Bitmap)和布隆过滤器(Bloom Filter)两种精巧的数据结构应运而生,成为解决海量数据处理问题的核心利器。
一、位图(Bitmap)
位图,又称位数组(Bit Array),是一种利用二进制位(bit)来表示数据是否存在的数据结构。其核心思想是:用一个比特位来标记某个元素对应的值,通常用“1”表示存在,用“0”表示不存在。
1. 基本原理与操作
假设我们需要处理一组范围在0到N-1之间的整数,判断某个整数是否存在。传统方法可能需要一个大小为N的布尔数组,每个元素占用一个字节(8位)。而位图则只需申请一个长度为N的比特数组,每个元素仅占1位,存储空间仅为传统方法的1/8。
主要操作包括:
- 设置(Set):将第i个比特位置为1,表示元素i存在。
- 清除(Clear):将第i个比特位置为0,表示元素i不存在。
- 查询(Test):检查第i个比特位是否为1,判断元素i是否存在。
2. 优势与局限
优势:
- 空间效率极高:特别适合表示稠密且范围有限的整数集合。
- 查询速度极快:时间复杂度为O(1),常数时间操作。
- 运算高效:支持高效的位运算(如与、或、非),便于进行集合的交、并、差操作。
局限:
- 适用范围受限:要求元素必须是整数,且范围不能过大。若元素ID范围是0到10^9,位图仍需约125MB内存(10^9 / 8 / 1024 / 1024)。若范围稀疏(如只有少数几个大数值),则空间浪费严重。
- 无法处理非整数数据:无法直接处理字符串、对象等复杂数据类型。
3. 典型应用场景
- 操作系统中的磁盘块管理、内存页管理。
- 数据库中的快速查询索引(如某些数据库的位图索引)。
- 网络爬虫的URL去重(需将URL哈希为整数)。
- 大数据场景下的用户签到统计、活跃用户判断等。
二、布隆过滤器(Bloom Filter)
布隆过滤器由伯顿·布隆于1970年提出,它是一种概率型数据结构,用于判断一个元素是否在一个集合中。其核心特点是:空间效率和查询时间都远超一般算法,但代价是存在一定的误判率(False Positive),即可能会将不存在的元素误判为存在。但绝不会将存在的元素误判为不存在(False Negative)。
1. 基本原理
布隆过滤器由一个长度为m的比特数组(位图)和k个相互独立的哈希函数组成。
添加元素过程:
当一个元素被加入集合时,通过k个哈希函数计算出该元素的k个哈希值,将比特数组中对应的这k个位置置为1。
查询元素过程:
当需要查询一个元素是否存在时,同样通过k个哈希函数计算出k个哈希值,然后检查比特数组中对应的k个位置是否都为1。如果全部为1,则认为元素“可能存在”于集合中;如果有任何一个位置为0,则元素“肯定不存在”于集合中。
2. 优势与局限
优势:
- 空间和时间效率极高:插入和查询操作都是O(k)的时间复杂度(k为哈希函数个数,通常很小)。空间消耗远低于存储元素本身(如存储10亿个电子邮件地址,传统方式需GB级内存,而布隆过滤器可能只需数百MB)。
- 支持任意数据类型:只要哈希函数能处理,即可支持字符串、对象等。
- 安全无漏:不存在“假阴性”,即不会漏报。
局限:
- 存在误判率:这是其最核心的缺点。随着元素增多,比特数组中1的比例增大,误判率会上升。
- 无法删除元素:由于多个元素可能共享同一个比特位,将某位置0可能会导致其他元素被误判为不存在。虽然存在可删除的变种(如计数布隆过滤器),但会牺牲更多空间。
- 无法获取元素本身:它只是一个“过滤器”,只能判断是否存在,无法存储或取出元素。
3. 参数设计与误判率
布隆过滤器的性能由三个参数决定:
- 比特数组长度 m
- 哈希函数个数 k
- 预计要插入的元素数量 n
误判率 p 的近似公式为:p ≈ (1 - e^(-k * n / m))^k。在实际设计中,通常会根据可接受的误判率 p 和预计元素数量 n,来计算出所需的 m 和 k。例如,当 p=0.01(1%),n=1亿时,大约需要 958,505,912 比特(约114MB)和7个哈希函数。
4. 典型应用场景
- 缓存穿透防护:在查询缓存之前,先用布隆过滤器判断数据是否存在,避免对不存在的数据发起昂贵的数据库查询。
- 网页爬虫去重:快速判断一个URL是否已被爬取过。
- 垃圾邮件过滤:判断一个邮件地址是否为垃圾邮件发送者(黑名单)。
- 分布式系统:如Google Bigtable、Apache Cassandra等数据库使用它来减少对不存在的行的磁盘查找。
- 网络路由:用于网络包转发中的路由查找。
三、位图与布隆过滤器的对比与结合
虽然两者都基于位数组,但设计目标不同:
- 位图是精确的、确定性的数据结构,适用于元素范围已知且稠密的整数集合。
- 布隆过滤器是概率性的、节省空间的数据结构,适用于元素范围未知、稀疏或非整数的大规模集合,并能容忍一定的误判率。
在实际应用中,两者可以结合使用。例如,在处理海量用户ID时,可以先使用位图处理连续且密集的小ID段,再使用布隆过滤器处理稀疏的大ID段,从而在保证效率的最大化节省空间。
###
位图和布隆过滤器以其极致的空间效率和查询速度,成为处理海量数据不可或缺的工具。理解它们的原理、优势、局限及适用场景,对于架构师和开发者设计高性能、高可扩展的系统至关重要。在面对海量数据问题时,不妨首先考虑:能否用一把“比特”的尺子来衡量?或许,答案就藏在这简洁而强大的二进制位之中。