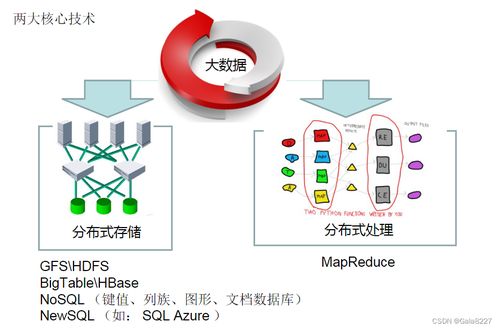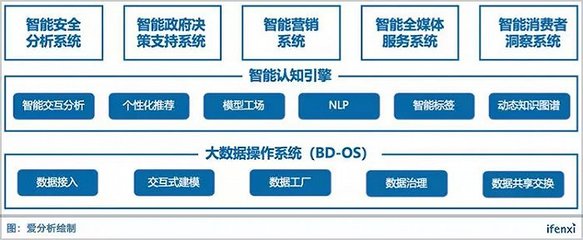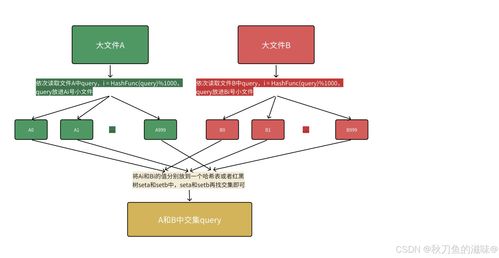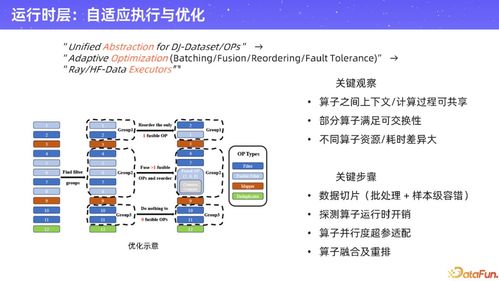
在人工智能飞速发展的今天,高质量、大规模的数据已成为驱动模型性能突破的核心燃料。数据的获取、清洗、标注与处理过程往往繁琐、低效且成本高昂,成为制约AI应用落地的关键瓶颈。阿里云通义实验室重磅开源了其自主研发的“datajuicer”多模态数据处理引擎,旨在通过一套标准化、自动化、高效能的工具链,彻底革新AI数据工程的现有范式,为开发者与研究者赋能。
一、多模态数据处理的“瑞士军刀”
datajuicer并非一个单一工具,而是一个集成了丰富算子(Operators)的综合性处理引擎。它深度支持文本、图像、音频、视频等多模态数据,提供从原始数据收集、质量评估、自动清洗、过滤、到数据增强、格式转换等一系列流程化操作。其核心设计理念是“配置即流水线”,用户通过简单的YAML配置文件,就能灵活组合上百种预置算子,构建满足特定任务需求的定制化数据处理流水线,极大地提升了开发效率与实验迭代速度。
二、引领新范式的三大核心优势
- 标准化与自动化:传统数据处理依赖大量人工编写脚本,流程分散且难以复用。datajuicer将通用处理步骤封装为标准算子,实现了处理流程的模块化与自动化。这不仅降低了使用门槛,更保证了处理过程的一致性与可复现性,使得数据工程能够像软件工程一样,进行规范的版本管理和质量管控。
- 以模型为中心的质量优化:区别于单纯基于规则的数据清洗,datajuicer创新性地引入了“以模型评估数据,以数据优化模型”的闭环思想。它集成了多种基于预训练模型的评估指标(如文本的困惑度、多样性,图像的审美评分、图文相关性等),能够智能评估数据质量,并据此进行精准过滤与增强,确保“喂”给AI模型的是高营养“饲料”。
- 卓越的性能与可扩展性:引擎底层针对大规模数据处理进行了深度优化,支持分布式计算,能够轻松处理TB乃至PB级的数据集。其开放的架构允许用户轻松自定义和接入新的算子或质量评估模型,社区生态的持续丰富将使其能力不断进化。
三、赋能千行百业的应用前景
datajucer的开源,将首先惠及AI研究与开发社区。无论是训练大语言模型(LLM)、多模态大模型,还是开发垂直领域的专用模型,研究者都可以利用它快速构建高质量的训练与评测数据集,将精力更多地聚焦于模型架构与算法创新。
更进一步,它有望推动各行业AI应用的数据基础设施升级。在金融、医疗、教育、内容创作、智能驾驶等领域,都存在大量非结构化、多模态的数据处理需求。datajucer提供的标准化方案,能帮助企业高效地挖掘自有数据价值,构建领域知识库,加速智能化转型。
四、开源共建,开启数据工程新篇章
通义实验室将datajucer以Apache 2.0协议开源,体现了其推动AI基础设施开放的决心。开源意味着透明、协作与共享。全球开发者可以共同参与工具链的完善,贡献新的算子与评估方法,分享针对不同场景的最佳实践配置,从而共同构建一个更强大、更智能的数据处理生态系统。
****
datajucer的发布,标志着AI数据工程从“手工作坊”模式迈向“工业化流水线”模式的关键一步。它通过提供一套强大、灵活、智能的多模态数据处理标准工具,不仅解决了当下的效率痛点,更从方法论层面引领了以数据质量为核心、以自动化为手段的新范式。随着社区的壮大与技术的迭代,datajucer有望成为AI时代数据处理的基石工具,为人工智能的下一轮突破奠定坚实的数据根基。