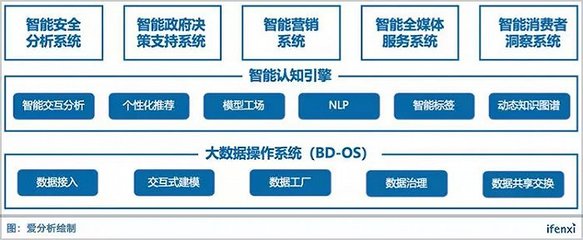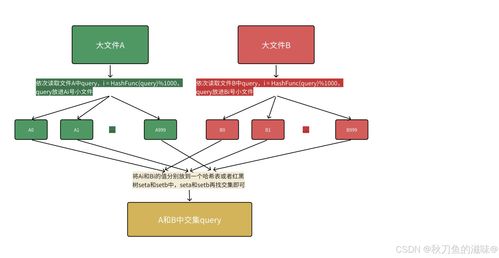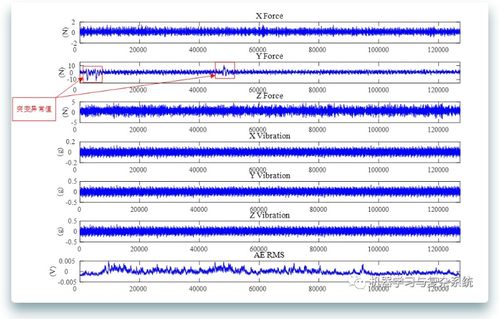
在数据分析与处理的流程中,异常数据的处理是至关重要的一环。它直接影响模型的准确性、决策的可靠性以及最终结论的有效性。本篇将系统探讨异常数据的识别、成因分析以及科学的处理策略。
一、 什么是异常数据?
异常数据,又称离群点,是指与数据集中其他观测值存在显著差异的数据点。这种差异可能源于测量误差、录入错误、系统故障,也可能反映了真实的罕见事件或新的模式。因此,处理异常数据并非简单地“删除”,而是需要审慎地诊断与判断。
二、 异常数据的识别方法
1. 统计方法:基于数据的分布假设,如使用Z分数(标准差法)或箱线图(IQR法)来划定正常值的范围,超出阈值的数据点被视为异常。
2. 可视化方法:通过散点图、直方图、时间序列图等直观地发现偏离主体分布的数据点。可视化是初步筛查的有力工具。
3. 机器学习方法:对于高维或复杂数据,可采用聚类算法(如DBSCAN)、孤立森林或一类支持向量机等无监督学习算法进行自动检测。
三、 异常数据的常见成因
- 数据采集错误:传感器故障、人工录入失误、数据传输丢失等。
- 业务操作事件:特定的促销活动、系统上线、节假日效应等导致的数据波动。
- 自然变异:小概率但真实发生的事件,如金融市场的剧烈波动、设备突发故障。
四、 异常数据的处理策略
处理策略的选择取决于异常数据的成因、数量以及对分析目标的影响。
- 直接删除:适用于确认为错误且数量很少的异常值,且删除后不影响数据整体代表性。
- 修正或填补:若能推断出真实值或合理值(如通过前后数据插值、使用均值/中位数),可进行修正。对于时间序列数据,此法尤为常见。
- 保留并分析:如果异常点代表重要的业务信息或潜在新模式(如欺诈检测中的异常交易),则应予以保留,并可能需要进行单独建模或深入分析。
- 数据转换:通过对数转换、Box-Cox转换等方法减弱异常值的极端影响,使其更符合模型的假设。
- 使用鲁棒性方法:在建模时选择对异常值不敏感的算法(如使用决策树代替线性回归),或采用鲁棒的统计量(如中位数代替平均数)。
五、 最佳实践与注意事项
- 记录处理过程:对任何异常数据的处理都应详细记录其识别方法、处理方式和理由,保证分析过程的可追溯性与可复现性。
- 结合业务知识:统计上的异常不一定是业务上的异常,必须与领域专家沟通,理解数据背后的业务逻辑。
- 分而治之:有时可以将数据分为“正常”与“异常”两部分分别建模,以获得更精准的洞察。
结论
异常数据处理没有一成不变的“金科玉律”。一个负责任的数分师或数据科学家,需要像侦探一样,综合运用技术工具与业务理解,对每一个异常点进行诊断,从而做出最有利于达成分析目标的决策。将异常数据处理视为探索数据故事的一部分,而不仅仅是数据清洗中的一个步骤,往往能带来意想不到的发现与价值。