随着数字经济的深入发展,数据已成为继土地、劳动力、资本、技术之后的第五大生产要素。如何高效、可靠、智能地处理海量、多源、异构的数据,是大数据技术发展的核心命题。本文将对主流的大数据处理技术进行系统性与分析,梳理其技术脉络与适用场景。
一、数据处理的核心范式与架构演进
大数据处理技术并非单一技术,而是一个包含数据采集、存储、计算、分析与应用的庞大技术生态。其发展主要围绕两大核心范式展开:批处理与流处理。
- 批处理(Batch Processing):面向历史、静态的大规模数据集,进行高吞吐、离线计算。其代表性技术是 Hadoop MapReduce。它通过“分而治之”的思想,将任务分解(Map)与汇总(Reduce),实现了在廉价商用硬件集群上处理PB级数据的能力,奠定了大数据工业化的基石。其磁盘I/O开销大、延迟高的缺点催生了新一代批处理框架,如 Apache Spark。Spark基于内存计算的RDD(弹性分布式数据集)模型,将中间结果缓存于内存,使迭代计算和交互式查询性能提升数个量级,并统一了批处理、流处理、机器学习等多种计算场景。
- 流处理(Stream Processing):面向实时、连续的数据流,进行低延迟、在线计算。早期的 Apache Storm 实现了真正的逐条处理,延迟极低。Apache Flink 异军突起,其核心设计是“以流为核心,批是流的特例”。Flink提供了精确的事件时间(Event Time)处理、状态管理和容错保证,在实时计算、复杂事件处理领域优势明显。而Spark的 Structured Streaming 则基于其批处理引擎,通过“微批”模式提供了高吞吐的准实时处理能力,降低了流处理的使用门槛。
架构演进趋势:从早期的Lambda架构(批层+速度层),到试图统一批流处理的Kappa架构(全流处理),再到如今以 Apache Flink 和 Apache Spark 为代表的流批一体架构,技术正朝着简化架构、降低运维成本、保证数据一致性的方向演进。
二、关键组件与技术生态分析
一个完整的大数据处理平台通常由以下关键组件构成:
- 资源管理与调度:Apache YARN 曾是Hadoop 2.0的核心,负责集群资源的管理与调度。如今,更通用的容器化资源调度器 Kubernetes 正成为云原生大数据处理的事实标准,提供了更灵活的部署、扩缩容和混部能力。
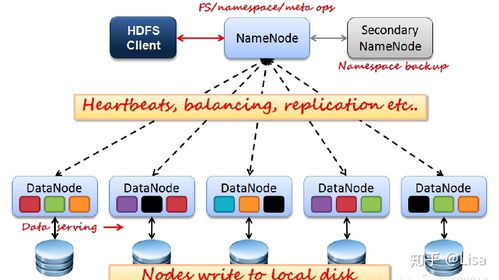
- 分布式存储:HDFS 作为经典的分布式文件系统,为批处理提供了可靠的存储底座。对象存储(如AWS S3、阿里云OSS)因其无限扩展性和低成本,正逐渐成为云上数据湖的首选存储。
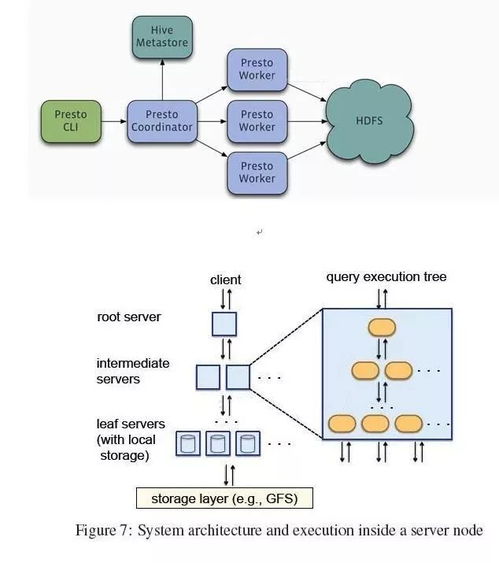
- 数据仓库与湖仓:传统数据仓库(如Teradata)转向MPP架构的 Apache Hive、Presto/Trino(交互式查询)。为解决数据湖(存储原始数据)管理混乱、数据质量差的问题,湖仓一体(Lakehouse) 概念兴起,其代表 Apache Iceberg、Apache Hudi、Delta Lake,在数据湖之上提供了ACID事务、模式演进、高效upsert等数据仓库级的管理能力。
- 消息队列与摄入:实时数据流的入口,Apache Kafka 凭借高吞吐、可持久化、分布式特性,成为连接数据源与流处理引擎的“中枢神经系统”。
三、挑战与未来趋势
尽管技术已日臻成熟,但仍面临诸多挑战:
- 实时智能:从“实时计算”走向“实时智能”,即流处理系统需要深度集成机器学习(ML)和人工智能(AI)能力,实现实时特征计算、模型推理与更新。
- 易用性与一体化:简化开发、运维流程,降低技术复杂度。Serverless 化的大数据处理服务,以及面向数据开发者的 DataOps、MLOps 实践,正成为关键。
- 云原生与成本优化:计算存储分离、容器化、弹性伸缩已成为云上标配。未来的焦点在于通过智能调度、混部、冷热数据分层等技术进一步优化总体拥有成本(TCO)。
- 数据安全与治理:在数据驱动业务的隐私计算、数据脱敏、全域血缘追踪、数据质量监控等治理工具变得至关重要。
###
大数据处理技术已从早期追求“存得下、算得了”的规模能力,发展到如今追求“算得快、用得好、管得住”的质量与效率阶段。技术选型没有银弹,需紧密结合业务场景(延迟要求、数据规模、精确性)、团队技能和成本预算。融合流批一体、云原生、AI增强的智能化数据处理平台,将是支撑企业数字化转型的核心引擎。